
Как использовать команду sed в Linux
Гайд в разделе Linux "Как использовать команду sed в Linux" содержит информацию, советы и подсказки, которые помогут изучить самые важные моменты и тонкости вопроса….
 Fatmawati Achmad Zaenuri / Shutterstock
Fatmawati Achmad Zaenuri / Shutterstock
Это может показаться безумным, но команда sed Linux – это текстовый редактор без интерфейса. Вы можете использовать его из командной строки для управления текстом в файлах и потоках. Мы покажем вам, как использовать его силу.
Сила sed
Команда sed немного похожа на шахматы: требуется час, чтобы изучить основы, и целую жизнь, чтобы овладеть ими (или, по крайней мере, много практики). Мы покажем вам выбор начальных гамбитов в каждой из основных категорий функций sed.
sed – это редактор потока, который работает с конвейерным вводом или файлами текста. Однако у него нет интерфейса интерактивного текстового редактора. Скорее, вы даете инструкции, которым он должен следовать при работе с текстом. Все это работает в Bash и других оболочках командной строки.
С помощью sed вы можете делать все следующее:
- Выделить текст
- Заменить текст
- Добавить строки в текст
- Удалить строки из текста
- Изменить (или сохранить) исходный файл.
Мы структурировали наши примеры, чтобы представить и продемонстрировать концепции, а не создавать самые краткие (и наименее доступные) команды sed. Однако функции сопоставления с образцом и выбора текста в sed сильно зависят от регулярных выражений (regexes). Вам понадобится некоторое знакомство с ними, чтобы извлечь максимальную пользу из sed.
Простой пример
Во-первых, мы собираемся использовать echo для отправки текста в sed через канал и заменить sed часть текста. Для этого мы набираем следующее:
echo howtogonk | sed ‘s / gonk / geek /’
Команда echo отправляет «howtogonk» в sed, и применяется наше простое правило подстановки («s» означает подстановка).sed ищет во входном тексте вхождение первой строки и заменяет любые совпадения второй.
Строка «gonk» заменяется на «geek», и новая строка печатается в окне терминала .
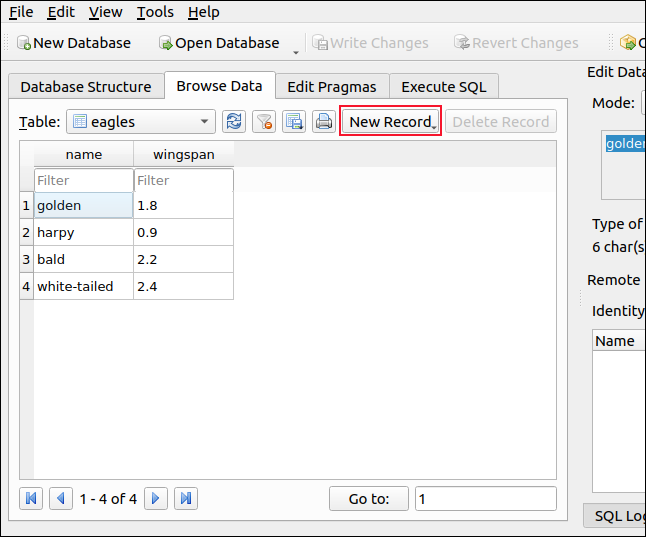
Подстановки, вероятно, являются наиболее частым использованием sed. Однако, прежде чем мы сможем глубже погрузиться в замены, нам нужно знать, как выделять и сопоставлять текст.
Выбор текста
Нам понадобится текстовый файл для наших примеров. Мы воспользуемся тем, который содержит подборку стихов из эпической поэмы Сэмюэля Тейлора Кольриджа «Иней древнего мореплавателя».
Мы набираем следующее, чтобы взглянуть на него с меньшими затратами:
меньше coleridge .txt

Чтобы выбрать несколько строк из файла, мы предоставляем начальную и конечную строки диапазона, который мы хотим выбрать. Одно число выбирает эту строку.
Чтобы извлечь строки с первой по четвертую, мы вводим следующую команду:
sed -n ‘1,4p’ coleridge.txt
Обратите внимание на запятую между 1 и 4. Буква p означает «печатать совпадающие строки». По умолчанию sed печатает все строки. Мы бы увидели весь текст в файле с соответствующими линиями, напечатанными дважды. Чтобы предотвратить это, мы будем использовать параметр -n (тихо) для подавления несоответствующего текста.
Мы меняем номера строк, чтобы мы могли выбрать другой стих, как показано ниже:
sed -n ‘6,9p’ coleridge.txt
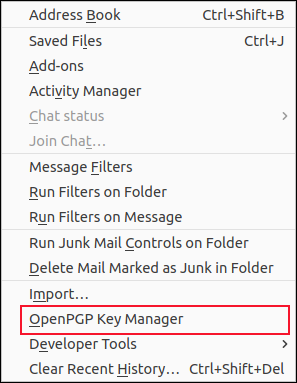
Мы можем использовать параметр -e (выражение), чтобы сделать множественный выбор. С помощью двух выражений мы можем выбрать два стиха, например:
sed -n -e ‘1,4p’ -e ’31, 34p ‘coleridge.txt
Если мы уменьшим первое число во втором выражении, мы можем вставить пробел между двумя стихами. Набираем следующее:
sed -n -e ‘1,4p’ -e ’30, 34p ‘coleridge.txt
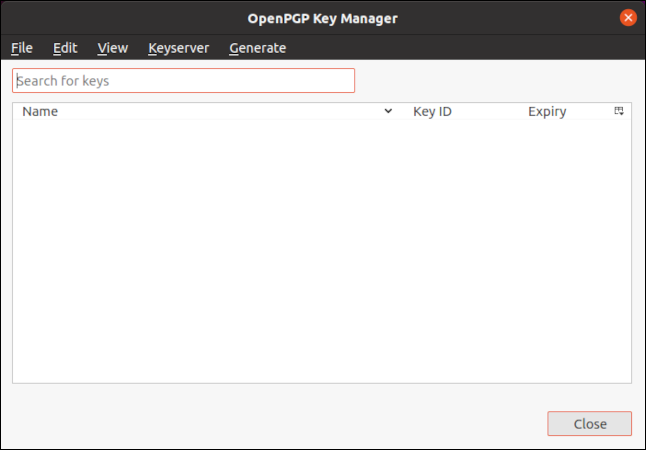
Мы также можем выбрать начальную строку и скажите sed пройти по файлу и распечатать чередующиеся строки, каждую пятую строку или пропустить любое количество строк. Команда аналогична тем, которые мы использовали выше для выбора диапазона. Однако на этот раз для разделения чисел мы будем использовать тильду (~) вместо запятой.
Первое число указывает на начальную строку. Второе число сообщает sed, какие строки после начальной строки мы хотим видеть. Число 2 означает каждую вторую строку, 3 означает каждую третью строку и т. Д.
Мы набираем следующее:
sed -n ‘1 ~ 2p’ coleridge.txt
Вы не всегда будете знать, где в файле находится искомый текст, а это значит, что номера строк не всегда помогут. Однако вы также можете использовать sed для выбора строк, содержащих совпадающие текстовые шаблоны. Например, давайте извлечем все строки, которые начинаются с «And».
Знак вставки (^) обозначает начало строки. Мы заключим наш поисковый запрос в косую черту (/). Мы также добавляем пробел после «И», поэтому такие слова, как «Android», не будут включены в результат.
Поначалу чтение сценариев sed может быть затруднительным. / P означает «печать», как и в командах, которые мы использовали выше. Однако в следующей команде перед ней идет косая черта:
sed -n ‘/ ^ And / p’ coleridge.txt
Три строки, начинающиеся с « И »извлекаются из файла и отображаются для нас.
Выполнение замен
В нашем первом примере мы показали вам следующий базовый формат для замены sed:
echo howtogonk | sed ‘s / gonk / geek /’
s сообщает sed, что это подстановка. Первая строка – это шаблон поиска, а вторая – текст, которым мы хотим заменить совпадающий текст. Конечно, как и во всем Linux, дьявол кроется в деталях.
Мы вводим следующее, чтобы заменить все вхождения «дня» на «неделю» и дать мореплавателю и альбатросу больше времени для связи:
sed -n ‘s / day / week / p’ coleridge .txt
В первой строке изменяется только второе вхождение «дня». Это потому, что sed останавливается после первого совпадения в строке. Мы должны добавить «g» в конце выражения, как показано ниже, чтобы выполнить глобальный поиск и обработать все совпадения в каждой строке:
sed -n ‘s / day / week / gp’ coleridge.txt
Соответствует трем из четырех в первой строке. Поскольку первое слово – «День», а sed чувствителен к регистру, он не считает, что этот экземпляр совпадает с «днем».
Мы вводим следующее, добавляя i к команде по адресу конец выражения для указания нечувствительности к регистру:
sed -n ‘s / day / week / gip’ coleridge.txt
Это работает, но вы не всегда можете включать регистрозависимость для всего. В этих случаях вы можете использовать группу регулярных выражений, чтобы добавить зависящую от шаблона регистронезависимость.
Например, если мы заключаем символы в квадратные скобки ([]), они интерпретируются как «любой символ из этого список символов ».
Мы вводим следующее и включаем« D »и« d »в группу, чтобы гарантировать соответствие как« Day », так и« day »:
sed -n ‘s / [Dd] ay / week / gp ‘coleridge.txt
Мы также можем ограничить замену разделами файла. Скажем, наш файл содержит странный интервал в первом стихе. Мы можем использовать следующую знакомую команду, чтобы увидеть первый стих:
sed -n ‘1,4p’ coleridge.txt
Мы найдем два пробела и заменим их одним. Мы сделаем это глобально, чтобы действие повторялось по всей строке. Для ясности, шаблон поиска – это пробел, пробел со звездочкой (*), а строка подстановки – это один пробел. 1,4 ограничивает замену первыми четырьмя строками файла.
Мы объединили все это в следующей команде:
sed -n ‘1,4 s / * / / gp’ coleridge.txt
Это прекрасно работает! Здесь важна схема поиска. Звездочка (*) обозначает ноль или более предшествующих символов, то есть пробела. Таким образом, шаблон поиска ищет строки из одного или более пробелов.
Если мы заменим один пробел на любую последовательность из нескольких пробелов, мы вернем файл с обычным интервалом, с одним пробелом между ними. слово. В некоторых случаях это также заменит единичный пробел на единичный пробел, но это не повлияет ни на что отрицательно – мы все равно получим желаемый результат.
Если мы введем следующее и сократим шаблон поиска до один пробел, вы сразу поймете, почему мы должны включить два пробела:
sed -n ‘1,4 s / * / / gp’ coleridge.txt
Поскольку звездочка соответствует нулю или более предшествующих символов, она видит каждый символ, не являющийся пробелом, как «нулевой пробел» и применяет к нему замену .
Однако, если мы включим два пробела в шаблон поиска, sed должен найти хотя бы один символ пробела, прежде чем применить замену. Это гарантирует, что непробельные символы останутся нетронутыми.
Мы вводим следующее, используя -e (выражение), которое мы использовали ранее, что позволяет нам делать две или более замены одновременно:
sed -n -e ‘s / motion / flutter / gip’ -e ‘s / ocean / gutter / gip’ coleridge.txt
Мы можем добиться того же результата, если будем использовать точку с запятой (,) для разделения двух выражений, например:
sed -n ‘s / motion / flutter / gip, s / ocean / gutter / gip ‘coleridge.txt
Когда мы поменяли местами «день» на «неделю» в следующей команде, экземпляр «день» в выражении «хорошо день» также был заменен :
sed -n ‘s / [Dd] ay / week / gp’ coleridge.txt
Чтобы предотвратить это, мы можем пытаться заменить только строки, соответствующие другому шаблону. Если мы изменим команду так, чтобы вначале был шаблон поиска, мы будем рассматривать только те строки, которые соответствуют этому шаблону.
Мы вводим следующее, чтобы сделать наш шаблон соответствия словом «после»:
sed -n ‘/ after / s / [Dd] ay / week / gp’ coleridge.txt
Это дает
Более сложные замены
Давайте передохнем Колриджу и воспользуемся sed для извлечения имен из файла etc / passwd.
Есть более короткие способы сделать это (подробнее об этом позже), но мы воспользуемся более длинным способом здесь, чтобы продемонстрировать другую концепцию. Каждый совпавший элемент в шаблоне поиска (называемый подвыражениями) может быть пронумерован (до девяти элементов). Затем вы можете использовать эти числа в своих командах sed для ссылки на определенные подвыражения.
Чтобы это работало, вы должны заключить подвыражение в круглые скобки [()]. Перед круглыми скобками также должна стоять обратная косая черта (), чтобы они не рассматривались как обычный символ.
Для этого вы должны ввести следующее:
sed ‘s / ([^: ] *).* / 1 / ‘/ etc / passwd
Давайте разберемся с этим:
- sed’ s /: Команда sed и начало выражение подстановки.
- (: открывающая скобка [(], заключающая часть выражения, перед которой стоит обратная косая черта ().
- [^:] *: первая часть выражения поискового запроса содержит группу в квадратных скобках. Каретка (^) означает «нет» при использовании в группе. Группа означает, что любой символ, кроме двоеточия (:), будет принят как совпадение.
- ): закрывающая скобка [)] с предшествующей обратной косой чертой ().
- . *: это второе подвыражение поиска означает «любой символ и любое их количество».
- / 1: Подстановочная часть выражения содержит 1, перед которой стоит обратная косая черта (). Он представляет текст, соответствующий первому подвыражению.
- / ‘: закрывающая косая черта (/) и одинарная кавычка (‘) завершают команду sed.
Все это означает, что мы будем искать любую строку символов, не содержащую двоеточия (:), которая будет первым совпадением текста. Затем мы ищем что-нибудь еще в этой строке, которое будет вторым совпадением текста. Мы собираемся заменить всю строку текстом, соответствующим первому подвыражению.
Каждая строка в файле / etc / passwd начинается с имени пользователя, заканчивающегося двоеточием. Мы сопоставляем все до первого двоеточия, а затем подставляем это значение для всей строки. Итак, мы изолировали имена пользователей.
Затем мы заключим второе подвыражение в круглые скобки [()], чтобы мы могли ссылаться на него по номеру, также. Мы также заменим 1 на 2. Теперь наша команда заменит всю строку всем, начиная с первого двоеточия (:) до конца строки.
Мы вводим следующее:
sed / ([^:] *) (.*) / 2 / ‘/ etc / passwd
Эти небольшие изменения меняют смысл команды, и мы получаем все, кроме имен пользователей.
Теперь давайте посмотрим на быстрый и простой способ сделать это.
Наш поисковый запрос – от первого двоеточия (:) до конца строки . Поскольку наше выражение подстановки пустое (//), мы ничем не заменяем совпадающий текст.
Итак, мы набираем следующее, отрубая все от первого двоеточия (:) до конца строки, оставляя только имена пользователей:
sed ‘s /:.*// “/ etc / passwd
Давайте посмотрим на пример, в котором мы ссылаемся на первое и второе совпадения в одной команде.
У нас есть файл запятых (,) разделяя имя и фамилию. Мы хотим перечислить их как «фамилия, имя». Мы можем использовать cat, как показано ниже, чтобы увидеть, что находится в файле:
компьютерные фанаты.txt
Как и многие команды sed, следующая может сначала показаться непонятной:
sed ‘s /^(.*),(.*)$/ 2,1 / g’ geeks.txt
Это команда подстановки, как и другие, которые мы использовали, и шаблон поиска довольно прост. Мы разберем это ниже:
- sed ‘s /: обычная команда подстановки.
- ^: поскольку курсор не находится в группе ([]), это означает «Начало строки».
- (. *) ,: Первое подвыражение – это любое количество любых символов. Он заключен в круглые скобки [()], каждой из которых предшествует обратная косая черта (), поэтому мы можем ссылаться на него по номеру. Пока что весь наш шаблон поиска переводится как поиск от начала строки до первой запятой (,) для любого количества любых символов.
- (. *): Следующее подвыражение (снова) будет любым номер любого символа. Он также заключен в круглые скобки [()], которым предшествует обратная косая черта (), поэтому мы можем ссылаться на соответствующий текст по номеру.
- $ /: знак доллара ($) обозначает конец строки и позволяет продолжить поиск до конца строки. Мы использовали это просто, чтобы ввести знак доллара. Здесь он нам действительно не нужен, так как в этом сценарии звездочка (*) идет в конец строки. Прямая косая черта (/) завершает раздел шаблона поиска.
- 2,1 / g ‘: поскольку мы заключили наши два подвыражения в круглые скобки, мы можем ссылаться на оба из них по их номерам. Поскольку мы хотим изменить порядок, мы вводим их как «второе совпадение, первое совпадение». Перед числами должна стоять обратная косая черта ().
- / g: это позволяет нашей команде работать глобально в каждой строке.
- geeks.txt: файл, над которым мы работаем на.
Вы также можете использовать команду “Вырезать” (c) для замены целых строк, соответствующих вашему шаблону поиска. Мы вводим следующее, чтобы найти строку со словом «шея» в ней и заменить ее новой строкой текста:
sed ‘/ Neck / c Вокруг моего запястья был натянут’ coleridge.txt

Наша новая строка теперь появляется в нижней части нашего отрывка.
Вставка строк и текста
Мы также можем вставить новые строки и текст в наш файл. Чтобы вставить новые строки после любых совпадающих, мы воспользуемся командой «Добавить» (а).
Вот файл, с которым мы собираемся работать:
cat geeks.txt
Мы пронумеровали строчки, чтобы упростить отслеживание.
Мы вводим следующее для поиска строк, содержащих слово «He», и вставляем под ними новую строку:
sed ‘/ He / a – – & gt, вставлено! ‘ выродки.txt
Мы вводим следующее и включаем команду Insert (i), чтобы вставить новую строку над теми, которые содержат совпадающий текст:
sed ‘/ He / i – – & gt, вставлено! ‘ geeks.txt
Мы можем использовать амперсанд (&), который представляет исходный совпавший текст, чтобы добавить новый текст в соответствующую строку. 1, 2 и т. Д. Представляют собой совпадающие подвыражения.
Чтобы добавить текст в начало строки, мы будем использовать команду подстановки, которая соответствует всему в строке, в сочетании с предложением замены, которое объединяет наш новый текст с исходной строкой.
Для всего этого набираем следующее:
sed ‘s /.*/–& gt, Inserted & /’ geeks.txt
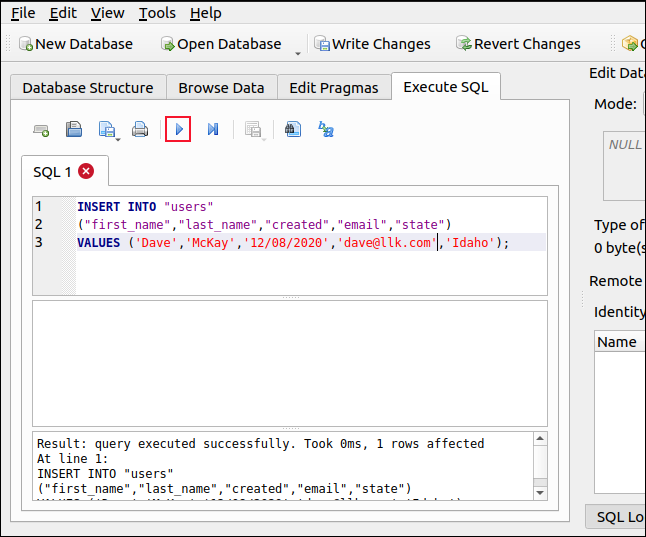
Набираем следующее, включая команду G, которая добавит пустую строку между каждой строкой:
sed ‘G’ гики.txt
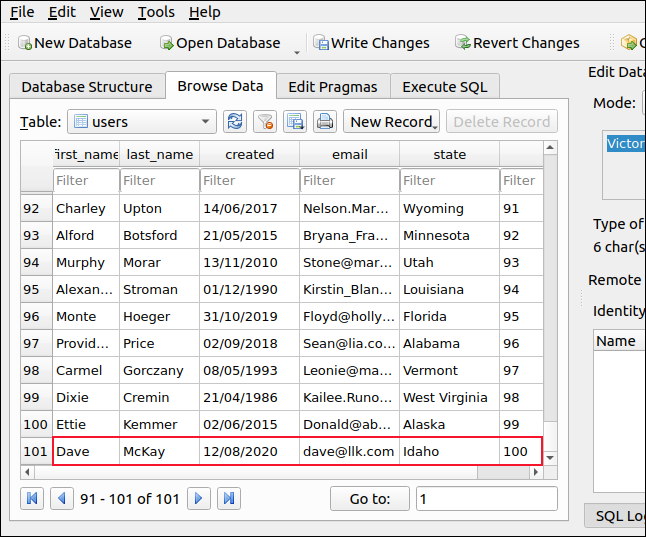
Если вы хотите добавить две или более пустых строк, вы можете использовать G, G, G, G, G и т. д.
Удаление строк
Команда Delete (d) удаляет строки, соответствующие шаблону поиска, или те, которые указаны с номерами строк или диапазонами.
Например, чтобы удалить третью строку, мы должны ввести следующее:
sed ‘3d’ geeks.txt
Чтобы удалить диапазон строк с четвертой по пятую, мы должны ввести следующее:
sed ‘4,5d’ geeks.txt
Чтобы удалить строки вне диапазона, мы используем восклицательный знак (!), как показано ниже:
sed ‘6,7! d’ geeks.txt
Сохранение ваших изменений
Пока все наши результаты распечатаны в окне терминала, но мы еще не сохранили их нигде. Чтобы сделать их постоянными, вы можете либо записать свои изменения в исходный файл, либо перенаправить их в новый.
Перезапись исходного файла требует некоторой осторожности. Если ваша команда sed неверна, вы можете внести некоторые изменения в исходный файл, которые будет трудно отменить.
Для некоторого спокойствия sed может создать резервную копию исходного файла перед выполнением своей команды.
Вы можете использовать параметр на месте (-i), чтобы указать sed записывать изменения в исходный файл, но если вы добавите к нему расширение файла, sed скопирует исходный файл в новый. Он будет иметь то же имя, что и исходный файл, но с новым расширением файла.
Чтобы продемонстрировать, мы найдем все строки, содержащие слово «Он», и удалим их. Мы также создадим резервную копию нашего исходного файла в новом, используя расширение BAK.
Чтобы сделать все это, мы набираем следующее:
sed -i’.bak ” /^.* He. * $ / D ‘geeks.txt
Мы вводим следующее, чтобы убедиться, что наш файл резервной копии не изменился:
cat geeks.txt.bak
Мы также можем ввести следующее, чтобы перенаправить вывод в новый файл и получить аналогичный результат:
sed -i’.bak ” ‘/ ^. * He. * $ / D ‘geeks.txt & gt, new_geeks.txt
Мы используем cat, чтобы подтвердить, что изменения были записаны в новый файл, как показано ниже:
cat new_geeks.txt
С помощью sed All That
Как вы, наверное, заметили, даже этот краткий учебник по sed довольно длинный. В этой команде много всего, и вы можете сделать с ней еще больше.
Тем не менее, будем надеяться, что эти базовые концепции обеспечили прочную основу, на которой вы сможете строить дальнейшие познания.